Matthew Lindfield Seager
Pasting (Confluence) HTML as Markdown
Confluence does not have an export to Markdown feature. For long-term conversion I will download as .docx and convert to Markdown with Pandoc but for quick uses (e.g. copying reference documentation for an LLM) that’s overkill.
This morning I iterated with Claude on a script that works very nicely. I use an Alfred workflow to trigger it on my Mac with ⌘ ⌥ M (for Markdown) but you could just as easily trigger it with FastScripts, RayCast, Keyboard Maestro or probably even Shortcuts (or adapt it for use on Linux or Windows).
The script assumes you have Pandoc installed and that you’ve just pressed ⌘ C on some selected HTML text.
osascript -e 'the clipboard as «class HTML»' \
| perl -ne 'print chr foreach unpack("C*",pack("H*",substr($_,11,-3)))' \
| perl -pe '
s/<span class="Apple-converted-space">[^<]*<\/span>/ /g;
s/ (data-[\w-]+|style)="[^"]*"//g;
s/<span class="code"[^>]*>(.*?)<\/span>/<code>$1<\/code>/g;
' \
| pandoc -f html -t gfm --wrap=none \
| perl -pe '
s/<div[^>]*>//g;
s/<\/div>//g;
s/<[^>]+>//g;
s/^``` code-block$/```/gm;
' \
| perl -0777 -pe '
s/^[^\S\n]+$//mg;
s/\n{3,}/\n\n/g;
'
I plan to update this post as I use it more and make small tweaks. It cleans up Confluence HTML nicely but I haven’t yet tested it with other sources.
If I remember, I’ll also write another post explaining the evolution from pbpaste -Prefer rtf | pandoc -f rtf -t markdown --wrap=none (which doesn’t work) to the monstrosity above.
Capistrano Branches
Capistrano (as of version 3.19.1) still defaults to deploying the master branch, even though GitHub, GitLab and BitBucket have all changed their default branch name to main.
The simplest fix for this is to add a line to config/deploy.rb which sets the branch to main:
# config/deploy.rb
set :branch, "main"
You can easily override that branch setting on a per-environment basis. For example, if you want to always deploy the currently checked-out (HEAD) branch when deploying to staging, override the :branch setting in config/deploy/staging.rb. The current branch can be obtained with git rev-parse --abbrev-ref HEAD so the command becomes:
# config/deploy/staging.rb
set :branch, `git rev-parse --abbrev-ref HEAD`.chomp
Getting more granular
Setting a global default and then overriding it per-environment is probably sufficient 95+% of the time, but what if you ever want to do something different?
If it’s a one-off thing, you could edit the local copy of config/deploy.rb or config/deploy/<env>.rb and deploy. As long as you don’t commit and push the changes to Git, Capistrano on your machine will use the branch you set, and everyone else will happily keep using the original setting from Git.
However, I found a better way (on StackOverflow) that doesn’t rely on you having to remember not to commit your changes. We will set up a workflow that gives us:
- a sane default for all environments
- the ability to set a new default for a specific environment
- the ability to override the default for any given deploy (for some or all environments)
First the code, then the explanation (lightly modified from my project’s README).
# config/deploy.rb
# config valid for current version and patch releases of Capistrano
lock "~> 3.19.1"
def branch_name(default_branch)
branch = ENV.fetch('BRANCH', default_branch)
if branch == '.'
`git rev-parse --abbrev-ref HEAD`.chomp
else
branch
end
end
# Uncomment one of these to set an app-wide default for all environments
# set :branch, "main"
# set :branch, branch_name("main")
set :application, "my_app"
# etc, etc
# config/deploy/production.rb
server "<hostname>", user: "deploy", roles: %w[app db web]
set :branch, branch_name("main")
# config/deploy/staging.rb
server "<hostname>", user: "deploy", roles: %w[app db web]
set :branch, branch_name(".")
And here’s the relevant section from my project’s README.md:
Deployment
Capistrano is used for deployment. By default the main branch will be deployed in production (more info in next section), so make sure all code has been committed (and pushed), then run:
> cap production deploy
A typical deployment takes less than 30 seconds and will finish with:
00:19 deploy:log_revision
01 echo "Branch main (at a087b4c40d8ef0031a0b90773c8511d8e873fa59) deployed as release 20240921040843 b…
✔ 01 deploy@<hostname> 0.067s
The last five releases are kept on the server (in theory allowing for easy rollback) but in practice it’s generally safer to revert the changes and deploy a new release (reference).
Deploying a different branch
The default branch has been set to “main” in config/deploy/production.rb (using set :branch, branch_name("main")), but you can override it by setting the BRANCH environment variable when running Capistrano:
> BRANCH=my-new-feature cap production deploy
Set the variable to . to deploy the current branch (a bit like the current working directory on *nix systems):
> BRANCH=. cap production deploy
The . shortcut also works in deploy files. We default to using the current branch in staging using:
# config/deploy/staging.rb
set :branch, branch_name(".")
P.S. On a bigger team you might not want to make it so easy to deploy a different branch to production. In that case, don’t include the banch_name method in production.rb:
# config/deploy/production.rb
server "<hostname>", user: "deploy", roles: %w[app db web]
set :branch, "main"
P.P.S. I deliberately commented out set :branch from config/deploy.rb. That way if I forget to set the branch for a new environment, Capistrano will attempt to use master and the deploy will fail. If you want new environments to default to something else, uncomment one of the set :branch lines in config/deploy.rb
Including Zeroes when Counting in SQL
TLDR: To count related records (and get a zero when there are none) use a LEFT JOIN. To count related records that match a certain criteria (and get a zero when there are none) use a CASE statement in the SELECT fields.
Longer Version
I had a table of school terms and a table of enrolments. Here’s a super simplified example using an INNER JOIN:
SELECT term.year, enrol.id
FROM term INNER JOIN enrol on term.term_id = enrol.term_id
| year | id |
|---|---|
| … | … |
| 2021 | 69423 |
| 2021 | 694170 |
| 2023 | 69423 |
| 2023 | 69584 |
| 2024 | 69456 |
To count the enrolments per year was a simple matter of adding a COUNT, changing it to a LEFT JOIN and adding the GROUP BY:
SELECT term.year, COUNT(enrol.id)
FROM term LEFT JOIN enrol on term.term_id = enrol.term_id
GROUP BY term.year
ORDER BY term.year DESC
| year | |
|---|---|
| 2024 | 1 |
| 2023 | 2 |
| 2022 | 0 |
| 2021 | 2 |
| … | … |
Note the count of 0 in 2022, that’s what I want! But then when I tried to add a WHERE clause to only get the enrolments where there was a possible flaw in the data, I stopped getting a zero count for the missing years:
SELECT term.year, COUNT(enrol.id)
FROM term LEFT JOIN enrol on term.term_id = enrol.term_id
WHERE enrol.raw_mark <> enrol.final_mark
GROUP BY term.year
ORDER BY term.year DESC
| year | |
|---|---|
| 2023 | 1 |
If I understand correctly, the WHERE clause is removing the rows (including the rows that only contain a term.year) before they get counted.
The solution (thanks to my DB guru friend TC) is to move the logic from the WHERE clause up into the SELECT. Also, now that there are blanks instead of nulls in the second column, we can go back to a regular INNER JOIN and still get the zero counts:
SELECT term.year,
COUNT(CASE WHEN enrol.raw_mark <> enrol.final_mark THEN 1 END)
FROM term INNER JOIN enrol on term.term_id = enrol.term_id
GROUP BY term.year
ORDER BY term.year DESC
| year | |
|---|---|
| 2024 | 0 |
| 2023 | 1 |
| 2022 | 0 |
| 2021 | 0 |
| … | … |
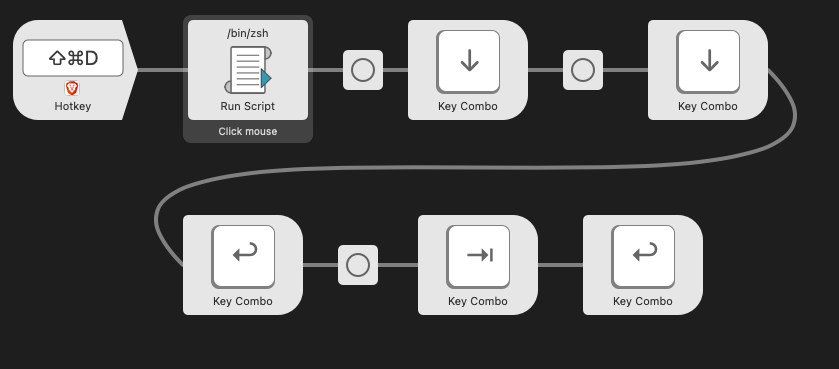
I’m using Alfred and cliclick to perform rudimentary UI automation to overcome a broken Salesforce implementation (can’t bulk delete):
- Click where the mouse is
- Press the down arrow twice (with a slight delay)
- Press enter
- Press tab
- Press enter
Changing the starting ID in a Rails app
While procrastinating working on a new Rails app, I didn’t want object IDs to start at 1 but neither did I want to deal with the various hassles of using a UUID instead of an integer for the ID. My compromise was to start the ID numbering with a multiple digit number.
This requires adding an execute statement (which is technically non-reversible) to your create_table migration:
class CreateUsers < ActiveRecord::Migration[7.1]
def change
create_table :users do |t|
t.string :name, null: false
t.string :email, null: false
t.timestamps
end
reversible do |direction|
direction.up do
# Set the starting ID on the users table so IDs don't start at 1
execute <<-SQL
INSERT INTO sqlite_sequence ('name', 'seq') VALUES('users', 2345);
SQL
end
direction.down do
# Do nothing (entry is automatically removed when table is dropped)
end
end
end
end
Note: The relevant sequence row gets dropped when the table gets dropped, so in this case there’s no need to define a down action. I’ve included an empty one anyway to make it clear this isn’t an oversight.
Now when I create my first user, their ID is 1 higher than the sequence I assigned… app.example.com/users/2346.
You can choose whatever starting number you want. If you’re running this on a different table, replace the ‘users’ portion with your own table name:
INSERT INTO sqlite_sequence ('name', 'seq') VALUES('<table>', 1734);
The above example is specific to SQLite (I’m using Litestack to simplify deployment) but presumably you could do something very similar with other databases.
I haven’t tested this but for PostgreSQL it should be as simple as changing the execute command above to:
SELECT setval('users_id_seq', 2345);
-- '<table>_id_seq' for other table names
If you try this with PostgreSQL, make you sure test the migration works in both directions.
The excitement (and nervousness) are building for my first ever conference talk!
Very excited (and nervous) to be accepted as a speaker at RubyConf Thailand in October 🥳
If all goes to plan I’ll be implementing a HTCPCP server live on stage.
Looking forward to listening to the keynote speakers!
Icon Set from a single image in 15 seconds
I built some AppleScript applets to launch Gmail to a specific account and Brave to a specific Profile (could also be done with Chrome) but I didn’t like the generic “Script” icon.

At first I just pasted my custom image into the “Get Info” window to update the icon but then when I made changes to the app and re-saved it, the icon got reset. I wanted to permanently updated the “applet.icns” file in the bundle but I didn’t want to spend an hour fiddling around with all the icon sizes.
Turns out, creating an icon set is super easy once you have your starting image:
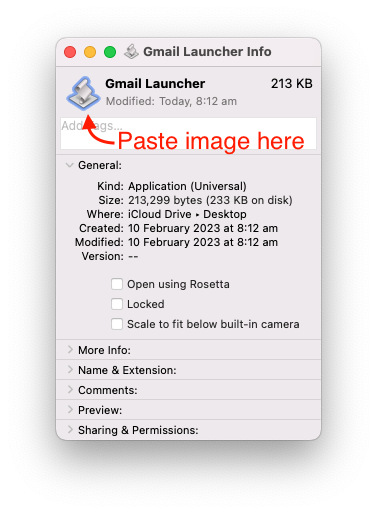
- Copy your image
- Paste it onto the icon in the Get Info window
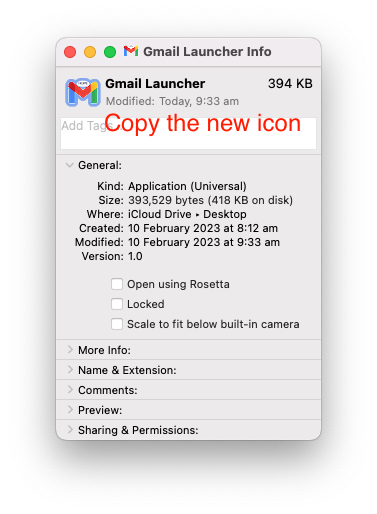
- Copy the new icon from the Get Info window
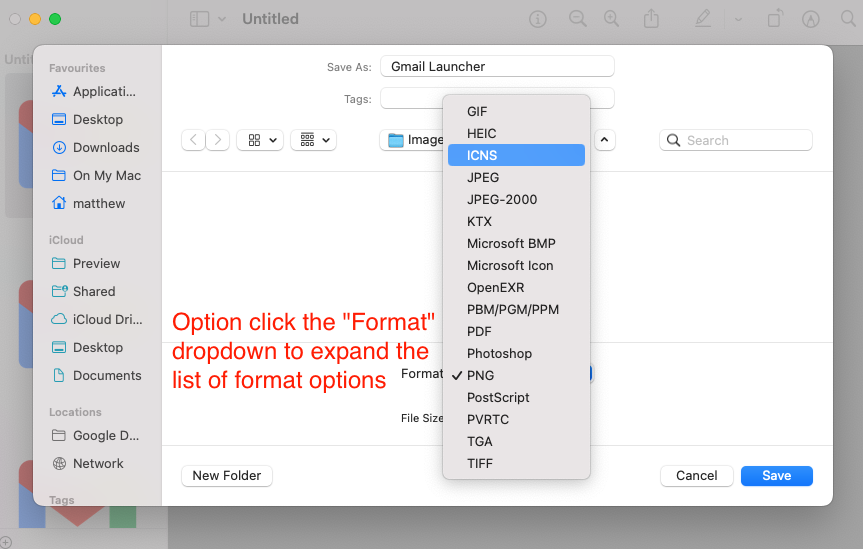
- “New from clipboard” in Preview (or just ⌘ N)
- Save…
- Option click the Format dropdown and choose ICNS
- Save
You now have an ICNS file with all 10 variations in it:
Step 2:
Step 3:
Step 6:
So happy to solve a longstanding performance bug! 🎉
I finally solved a hugely annoying performance bug in one of my Rails apps! To give you an idea of how bad it had gotten, just before the fix an admin page I use 5-10 times every Saturday was averaging 21,114.2 milliseconds per load!!! 😱 Although really, when the times are that large, milliseconds is probably the wrong unit of measurement… That page was taking 0.00024 days to load!!! And the trend was only getting worse!
That same page is now averaging 22.4 milliseconds, about 3 orders of magnitude quicker!
I’d been trying to figure it out for months but I was hampered by a combined lack of:
- motivation; public facing pages were “only” taking 2-4 seconds and no one had complained
- expertise; I’ve never had to solve performance problems on my own before
- tooling; I had inexplicable issues getting Rack Mini Profiler flamegraphs to work on the site, in development or on production 🤷♂️
The tooling problems were particularly frustrating so I owe a massive thank you to Nate Berkopec from Speedshop who not only puts out a ton of great content but was also very patient with my beginner questions about why my flamegraphs weren’t working. I didn’t end up figuring out that problem, but at Nate’s suggestion I switched to rbspy to create a flamegraph and within about an hour I’d figured out the problem that I’d previously spent months off and on trying to solve.
It turns out that every time I fetched a person from the database, my app was generating a random password for them. That process is a bit slow (possibly by design? to avoid timing attacks?? maybe???). Individually, 200 milliseconds to generate a password isn’t a big deal… but on the admin page I load a list of all the people, so every time a new person got added, the page slowed down by another 1/5 of a second 🤦♂️
In the end the fix was super simple, I now only generate the random password (and other default values) if the person isn’t already in the database:
# Before
after_initialize :set_default_values
# After
after_initialize :set_default_values, if: :new_record?
18 more characters to remove a 94,160% slow down! Plus now the user facing pages are down below 30 milliseconds too! 🥳
For future reference, here’s how I tracked down the issue:
- Installed rbspy using homebrew
- Obtained my web server process’ PID from
tmp/pids/server/pid - Captured a trace on my Mac using
sudo --preserve-env rbspy record --pid 86229 --format speedscope --subprocesses - [Not tested but could maybe combine the above two steps with something like
sudo --preserve-env rbspy record --pid `cat tmp/pids/server/pid` --format speedscope --subprocesses] - Request the offending page or pages then go back and end the rbspy recording with control-c
- Drag the resulting speedscope file from
~/Library/Caches/rbspyinto speedscope - Found the offending call at the very bottom of the flamegraph “stalactites”
CI on Github Actions with Rails 7, Postgres, esbuild, Tailwind CSS and StandardRB
After a bit of research and a lot of trial and error I finally got Github Actions working for CI on a Rails 7 (alpha 2) app that uses Postgres, esbuild and Tailwind CSS, plus StandardRB for formatting
It’s kind of hard to believe, but it seems you get it all for free!
Here’s what worked for me:
# test_and_lint.yml
name: Test and Lint
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build-and-test:
runs-on: ubuntu-latest
services:
postgres:
image: postgres
env:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
ports:
- 5432:5432
steps:
- uses: actions/checkout@v2
- uses: ruby/setup-ruby@v1
with:
bundler-cache: true
- name: Install yarn and build assets
run: |
yarn --frozen-lockfile
yarn build
yarn build:css
- name: Install psql
run: sudo apt-get -yqq install libpq-dev
- name: Build DB
env:
PGHOST: localhost
PGUSER: postgres
PGPASSWORD: postgres
RAILS_ENV: test
run: bin/rails db:setup
- name: Run Tests
env:
PGHOST: localhost
PGUSER: postgres
PGPASSWORD: postgres
RAILS_ENV: test
run: |
bundle exec rake test
bundle exec rake test:system
lint:
runs-on: ubuntu-latest
steps:
- name: standardrb
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
uses: amoeba/standardrb-action@v2
Big thanks to Andy Croll, his instructions were super helpful to get the basic build and test workflow working with Postgres.
Vincent Voyer’s instructions were helpful for the yarn installation step.
From there, I just needed to add the yarn build and yarn build-css commands to trigger the build steps defined in package.json.
Encrypted Credentials in Rails
Rails can encrypt keys for you. It encrypts and decrypts them using other keys. Once your keys have been decrypted using the other keys, you can look up your keys by their keys. If that sounds confusing, this post may be the key to getting a better understanding of Rails Credentials.
TL;DR
Learning 1: RAILS_ENV=production rails credentials:edit, RAILS_ENV=development rails credentials:edit and rails credentials:edit all do exactly the same thing. The way to edit per-environment credentials is by adding the --environment flag; rails credentials:edit --environment production.
Learning 2: Regardless of which file they’re defined in, credentials are accessed again using Rails.application.credentials.name or Rails.application.credentials.name[:child][:grandchild][:great_grandchild] if you nest credentials.
Learning 3: If an environment-specific credentials file is present, Rails will only look in that file for credentials. The default/shared credentials file will not be used, even if the secret is missing from the environment-specific file.
Bonus Tip: ActiveSupport::OrderedOptions is a handy sub-class of hash that gives you dynamic method based on hash key names and the option of raising an error instead of retuning nil if a requested hash key doesn’t have a value assigned.
That’s the short version. Read on if you’d like some additional context, a bit information about how the Credentials “magic” actually works and some practical implications. If you’re super bored/interested, read on beyond that for some mildly interesting trivia or edge cases.
A note on terminology As noted earlier, the term keys is very overloaded. Credentials, passwords or secrets are often referred to as keys, as in API key. Additionally, Rails Credentials uses a key to encrypt each credential file. Finally, hashes, the data type Rails Credentials uses to store decrypted credentials in memory, use keys to retrieve values. Which is why we can accurately but unhelpfully say, keys are encrypted by other keys and looked up by yet different keys. In an effort to avoid confusion I have used the following naming convention throughout this post:
- The term Credentials (upper case C) is shorthand for Rails Credentials, the overall Rails facility for storing secrets needed by your application.
- The terms credentials or credential (lower case C) refer to the actual application secret(s) you store using Credentials.
- The term “name” is used to refer to the hash key (or YAML key) of a credential.
- The term “file encryption key” is used to refer to the main secret that Credentials uses to encrypt a set of your credentials on disk.
- Any other unavoiable use of the word “key” will be preceded by a descriptor such as hash key, YAML key or API key.
Background
I’m using Rails’ built in Credentials feature to store Google Workspace API credentials. After seeing how easy it was to delete real Google Workspace users from the directory, I decided I really should be using the test domain Google generously allows education customers to set up. So after adding a Service Account to our test domain, it was time to separate the production credentials from the development/staging credentials.
My first thought was to run RAILS_ENV=production rails credentials:edit but when I did, the existing credentials file opened up. I then tried to specify the development environment to see if maybe I had it backwards but once again the same credentials file opened up.
There’s nothing in the Rails Guide on security about it but eventually I found a reference to the original PR for this feature which explains the need to specify the environment using the --environment flag.
Here are some of the things I learned while exploring this corner of Rails.
Learnings
1. RAILS_ENV has no effect on the rails credentials commands
The command rails credentials:edit, regardless of the value of RAILS_ENV, will always attempt to open and decrypt the default credentials file for editing; config/credentials.yml.enc. The way to change which environment you would like to edit credntials for is to use the --environment flag.
When dealing with the default credentials file, the encryption key is obtained from the RAILS_MASTER_KEY environment variable if it is set, otherwise the contents of config/master.key is tried. When you close the decrypted file, it is re-encrypted with the encryption key.
If you specify an environment using (for example) rails credentials:edit --environment production, then a different credentials file will be opened (or created) at config/credentials/production.yml.enc. This one might use the same encryption key or it might not. If the same RAILS_MASTER_KEY environment variable is set, it will use that to encrypt the file. If it isn’t set, it will use (or create on first edit) a different key stored in a correspondingly named file, config/credentials/production.key in our example.
Here’s a table showing 4 different credential commands, the files they maintain, and the location of the encryption keys used for each file:
| Command | Credentials File | Encryption key Environment Variable | Encryption Key File (if ENV VAR not set) |
|---|---|---|---|
rails credentials:edit |
config/credentials.yml.enc |
RAILS_MASTER_KEY |
/config/master.key |
rails credentials:edit --environment development |
/config/credentials/development.yml.enc |
RAILS_MASTER_KEY |
/config/credentials/development.key |
rails credentials:edit --environment test |
/config/credentials/test.yml.enc |
RAILS_MASTER_KEY |
/config/credentials/test.key |
rails credentials:edit --environment production |
/config/credentials/production.yml.enc |
RAILS_MASTER_KEY |
/config/credentials/production.key |
2. First level credentials are accessible as methods, child credentials must be accessed via their hash keys
With your credentials successfully stored, they can all be accessed within your Rails app (or in the console) via the Rails.application.credentials hash. The credential names in the YAML are symbolized so credential_name: my secret password can be accessed via Rails.application.credentials[:credential_name]. For your convenience, first level credentials are also made available as methods so you can access them using Rails.application.credentials.name.
If you nest additional credentials, they form a hash of hashes and can be accessed using standard hash notation. I can’t imagine why you’d want more than 2, maybe 3, levels in a real application but if you had six levels of nesting the way to access the deepest item would be Rails.application.credentials.name[:child][:grandchild][:gen_4][:gen_5][:gen_6]. Child credentials can’t be accessed as methods, you must use the hash syntax to access them: Rails.application.credentials.name[:child].
If you want an exception to be raised if a top level credential can’t be found, use the bang ! version of the method name: Rails.application.credentials.name!. Without this you’ll just get back nil. You will need to manually guard against missing child credentials yourself though. One way to do this would be Rails.application.credentials.name![:child].presence || raise(KeyError.new(":child is blank"))
3. Only one credentials file can be used in any given environment
If an environment-specific credentials file is present, Rails will only look in that file for credentials. The default credentials file will not be used, even if the requested credential is missing from the environment-specific file and set in the default file.
One implication of this is that, if you use environment specific files, you will need to duplicate any shared keys between files and keep them in sync when they change. I would love to see Credentials improved to first load the default credentials file, if present, with all its values and then load an environment-specific file, if present, with its values. Shared credentials could then be stored in the default file and be overridden (or supplemented) in certain environments.
Take aways
1. Environment-specific files introduce new challenges
Choosing to adopt environment-specific files means choosing to keep common credentials synchronised between files. Small teams may be better off sticking with namespaced credentials in the default file. To my mind, the neatest option is simply adding an environment YAML key where necessary:
# credentials.yml.enc
aws_key: qazwsxedcrfv # same in all environments
google:
development: &google_defaults
project_id: 12345678 # shared between all environments
private_key: ABC123
test:
<<: *google_defaults # exactly the same as development
production:
<<: *google_defaults
private_key: DEF456 # override just the values that are different
# Application
Rails.application.credentials.aws_key
Rails.application.credentials.google[Rails.env.to_sym][:project_id]
Rails.application.credentials.google[Rails.env.to_sym][:private_key]
If separate files are needed, I think the next best option would be to try to limit yourself to two files; one shared between dev, test and staging, and another one for production. However this will get messy the moment you need to access any production credentials in staging (for example). You’ll then need to either keep all 3 files fully populated or start splitting the contents of one or both of the files using the [Rails.env.to_sym] trick.
2. File Encryption Key sharing/storage
If you lose your file encryption Key, the contents of the encrypted file will also be lost. Individuals could store this file in local backups or store the contents of the file in their password manager.
If multiple team members need access, the file encryption key should be stored in a shared vault. I’m a big fan of 1password.com myself.
3. File Encryption Key rotation
One way to rotate your File Encryption Keys is to:
1. Run rails credentials:edit to decrypt your current credentials
2. Copy the contents of that file before closing it
3. Delete credentials.yml.enc and master.key (or other file pairs as necessary)
4. Re-run rails credentials:edit to create a new master.key
5. Paste the original contents in, then save and close. This will create a new credentials.yml.enc file
6. Update the copy in your password manager
7. Clear your clipboard history if applicable
Edge cases and trivia
If RAILS_MASTER_KEY is not set and the encryption key file (see table above) does not exist, a new encryption key will be generated and saved to the relevant file. The encryption key file will also be added to .gitignore. The new encyption key will not be able to decrypt existing credential files.
Whilst RAILS_MASTER_KEY lives up to it’s “master key” name and is used by all environment files, config/master.key does not and is not.
The --environment flag accepts either a space, --environment production, or an equals sign, --environment=production.
If you specify a credential name (YAML key) with a hyphen in it, the .name syntax won’t work. Similarly if you name a child credential with a hyphen, you will need to access it with a strange (to me) string/symbol hybrid. The required syntax is Rails.application.credentials[:'hyphen-name'] and Rails.application.credentials.name[:'child-hyphen-name'] respectively.
You can’t change the file encryption key by running credentials:edit and then changing the file encryption key whlie the credentials file is still open. The original file encryption key is kept in memory and used to re-encrypt the contents when the credentials file is closed.
Even though you don’t use RAILS_ENV to set the environment, the environment name you pass to the --environment flag should match a real envrionment name. If you run rails credentials:edit --environment foo, Rails will happily generate foo.yml.enc and foo.key but unless you have a Rails environment named foo the credentials will never be (automatically) loaded.
Some YAML files in Rails are parsed with ERB first. Credentials files are not so you can’t include Ruby code in your credentials file.
YAML does allow you to inherit settings from one section to another. By appending &foo to the end of a parent key you can “copy” all the child keys to another YAML node with <<: *foo. See the example in Takeaway 1 above for a fuller example.
In development, Rails.application.credentials will not have any credentials loaded (in @config) until after you first access one explicitly or access them all with Rails.application.credentials.config.
This may also be theoretically true in production, but in practice the production environment tries to validate secret_key_base at startup, thereby loading all the credentials straight away.
Whilst technically the credentials live in the Rails.application.credentials.config hash, Credentials delegates calls to the :[] and :fetch methods to :config. This allows us to drop the .config part of the method call.
Missing methods on Rails.application.credentials get delegated to :options. The options method simply converts theconfig hash into ActiveSupport::OrderedOptions, a sub-class of Hash. OrderedOptions is what provides the .name shortcuts and the .name! alternatives. I can think of a few other use cases where OrderedOptions would be handy! If you already have a hash you need to use ActiveSupport::InheritableOptions to convert it into an OrderedOptions collection.
Why Action Mailbox can't be used with Gmail
I’ve seen a few questions today about how to get Rails’ Action Mailbox working with Gmail so you can process Gmail messages in a Rails app. The short answer is:
- Gmail doesn’t support it
- Rails doesn’t support it
A longer answer, which I also posted on Stack Overflow in reply to the second question above, follows.
Action Mailbox is built around receiving email from a Mail Transfer Agent (MTA) in real time, not periodically fetching email from a mailbox. That is, it receives mail sent via SMTP, it doesn’t fetch mail (using IMAP or POP3) from another server that has already received it.
For this to work it is dependent on an external (to Rails) SMTP service receiving the email and then delivering the email to Action Mailbox. These external services are called “Ingresses” and, as at the time of writing, there are 5 available ingresses.
Of the five, four are commercial services that will run the required SMTP servers for you and then “deliver” the email to your application (usually as a JSON payload via a webhook).
You could already use those services in a Rails App and handle the webhooks yourself but Action Mailbox builds a standardised set of functionality on top. Almost like a set of rails to guide and speed the process.
In addition, the fifth ingress is the “Relay” ingress. This allows you to run your own supported MTA (SMTP server) on the same machine and for it to relay the received email to Action Mailbox (usually the raw email). The currently supported MTAs are:
To answer the specific questions about Gmail:
- How could they integrate that with Action Mailbox?
They couldn’t directly. They would need to also set up one of the 7 MTAs listed above and then somehow deliver the emails to that. The delivery could be accomplished with:
- Forwarding rules managed by the user at the mailbox level
- Dual delivery, split delivery or some other advanced routing rule managed by the admin at the domain level
- Would one use Gmail’s API, or would that not be appropriate for Action Mailbox?
Even if there were a way to have Gmail fire a webhook on incoming email (I’m not aware of any special delivery options outside the advanced routing rules above), there is currently no way to connect that theoretical webhook to Action Mailbox.
- If Gmail doesn’t work, what is different about SendGrid that makes it integrate appropriately?
Sendgrid (to use your example, the others work more or less the same way) offers an inbound mail handling API. Just as importantly, the Rails Team has built an incoming email controller to integrate with that API.
Given the lack of Gmail APIs and the lack of a Rails ingress controller, the only way I can think of that you could connect Action Mailbox to an existing Gmail mailbox would be for some other bit of code to check the mailbox, reformat the fetched email and then pose as one of the supported MTAs to deliver it to Action Mailbox.
It would be an interesting exercise, and would possibly become a popular gem, but it would very much be a kludge. A glorious kludge if done well, but a kludge nonetheless.
Tip for deploying a brand new Rails app
Hot tip, if you deploy a brand new Rails app to production and it doesn’t work, it might not be a problem with Ubuntu, Ansible, Capistrano, Nginx or Passenger… it might just be that it’s trying to show the “Yay! You’re on Rails!” page which only works in development 😩🙃
Before you spend hours researching and troubleshooting, throw this in your config/routes.rb file and see if it gets the site working:
root to: -> (env) do
[200, { 'Content-Type' => 'text/html' }, ['<h1>Hello world!</h1>']]
end
Goodbye Friday night ¯_(ツ)_/¯
Nearly skipped overcast.fm/+DJ5hZFTe… when I saw it was about service-based architectures but I’m glad I didn’t because the principles seemed just as relevant to dealing with errors in a monolithic architecture (even if the approach might need to vary)
Enterprise Identity Management on Rails - RailsConf 2020
Reflections on the RailsConf 2020 talk of Brynn Gitt & Oliver Sanford
Brynn and Oliver shared from their experience implementing Single Sign On (SSO) and Identity Management with various protocols and providers. It was interesting thinking about this from the vendor point of view, most of my experience with SSO has been as a customer trying to implement and troubleshoot SSO integrations.
A key lesson up front was how to think about identity when building (or expanding) a business to business (B2B) application, to avoid painting yourself into a corner. Consider:
- A single person may have multiple identities; they may be a member of multiple organisations, at the same time
- A single “identifier”, such as an email address, may apply to different users at different times e.g. if an organisation reuses an old email address for a new member
- A single organisation member may have multiple or mutable identifiers; e.g. for privileged accounts or in the case of name or email address change
- Different organisations will allow or require different Identity Providers
- Different Identity Providers have different implementations of the same protocols and standards
There is no single answer that will be correct in all circumstances but in most cases it makes sense to scope every person to an organisation. If you also need individual accounts there are two common ways to deal with that:
- have many one-person organisations (at least under the hood, I imagine there’d be good arguments not to expose that to customers)
- add individuals to a single “public” organisation (again, under the hood)
Within this first section Oliver briefly touched on the importance of observability and the need to log identity events. They can prove very useful when tuning a system or implementing new functionality.
The talk then went on to SAML (which is where most of my experience as a customer setting up SSO has been).
One tip was to use OmniAuth MultiProvider to make it easier to allow different customer organisations to each set up their own Identity Providers.
Another tip was to set up a flag you can turn on in production to log SAML assertions. This will allow you to assist customers as they figure out the required format and parameters while setting up SSO in their own organisation.
One last tip I want to remember is to use KeyCloak in development. It’s an open source Identity and Access Management system that can be used as an IDP in development (and can be launched simply using Docker).
After touching on just-in-time account provisioning, the rest of the talk covered SCIM - System for Cross-domain Identity Management. Implementing SCIM enables customers to create and manage accounts in your application directly from their Identity Provider (such as Okta). I’m very interested to dive into that topic a bit more, particularly with regards to how it might apply in the ed-tech space.
Calculating Dates in JavaScript
I was struggling recently to calculate dates using JavaScript. I wanted a minimum date to be two weeks from today but at the start of the day (midnight). In a Rails app (or a Ruby app with ActiveSupport) I would simply chain calculations on to the end of DateTime.now:
minimum_date = DateTime.now.beginning_of_day + 2.weeks
I figured I could do something similar in JavaScript so I researched out how to calculate the start of today (new Date().setHours(0, 0, 0, 0)) and how to get 14 days from now (day.setDate(day.getDate() + 14)). Separately they both worked, but no matter what I tried I couldn’t combine the two:
// Non-example 1
let minimumDate = new Date().setHours(0, 0, 0, 0).getDate() + 14
> TypeError: new Date().setHours(0, 0, 0, 0).getDate is not a function.
// Non-example 2
let startOfToday = new Date().setHours(0, 0, 0, 0)
let minimumDate = startOfToday.setDate(startOfToday.getDate() + 14)
> TypeError: startOfToday.getDate is not a function.
// Non-example 3
let now = new Date()
let twoWeeksFromNow = now.setDate(now.getDate() + 14)
let minimumDate = twoWeeksFromNow.setHours(0, 0, 0, 0)
> TypeError: twoWeeksFromNow.setHours is not a function.
Eventually I learned that both setHours() and setDate() were updating their receivers but returning an integer representation of the adjusted date (milliseconds since the epoch), not the date itself1,2.
With this knowledge in hand, one way to set the minimum date would be to just use a single variable:
let minimumDate = new Date()
minimumDate.setDate(minimumDate.getDate() + 14)
minimumDate.setHours(0, 0, 0, 0)
It works and it’s quite explicit but I don’t love that the variable name is (temporarily) wrong for the first two lines. I like my code to be self documenting and easy for future me to decipher (hence why I tried to use interim variables in Examples 2 & 3 to spell out the steps I’m taking).
As part of my exploration I went back to Ruby to figure out how I would solve the same problem without ActiveSupport. The clearest way seemed to be to create two (accurately named) dates:
now = Time.now
minimum_date = Time.new(now.year, now.month, now.day + 14)
Sure enough, we can do the same thing in JavaScript:
let now = new Date();
let minimumDate = new Date(now.getFullYear(), now.getMonth(), now.getDate() + 14)
Again, that works but it relies on knowledge of how the Date constructor works (that is, it’s not very explicit). Using the explicit option but extracting it into its own method makes my intent even clearer:
let minimumDate = twoWeeksFromNowAtStartOfDay()
function twoWeeksFromNowAtStartOfDay() {
let returnValue = new Date()
returnValue.setDate(minimumDate.getDate() + 14)
returnValue.setHours(0, 0, 0, 0)
return returnValue
}
1 Ruby tries to follow the Principle of Least Surprise. Mutating a Date object but returning a number is very suprising to me. The principle in JavaScript seems to be “expect the unexpected” ↩
2
I also learned that let is a way to declare a variable with a limited scope (whereas var creates a global variable). I had assumed that let was how you declared a constant and so I was surprised I was allowed to mutate the contents of the “constants”.
I later tested a variation of example 3 with const and it turns out I can mutate a date constant (see also footnote 1 about expecting the unexpected). I don’t want to go any further into this rabbit hole right now so the many questions this raises will remain unanswered for the time being.
// Using a "constant"
const now = new Date()
> undefined
now
> Sun May 17 2020 13:32:34 GMT+1000 (AEST)
now.setDate(now.getDate() + 14)
> 1590895954088
now
> Sun May 31 2020 13:32:34 GMT+1000 (AEST)
now.setHours(0, 0, 0, 0)
> 1590847200000
Sun May 31 2020 00:00:00 GMT+1000 (AEST)
Can ActiveStorage Serve Images for the Modern Web? - RailsConf
Reflections on Mark Hutter’s RailsConf 2020 talk
Mark shows that ActiveStorage has some nice features which make it a good option for serving images but points out that some of those options come at a price. For example, serving variants on the fly can be expensive.
Mark has a pragmatic answer on how to measure “is it fast enough?” along with some best practices on ensuring images served through ActiveStorage are performant:
- pre-process expected variants rather than doing it on the fly
- better yet, pre-process in the background so as not to block the humans (or admin humans) uploading images your site
- use eager loading to fetch associated attachment records (where appropriate) to prevent n+1 queries
- consider monkey patching
RepresentationsControllerif you need to cache ActiveStorage images cached using a CDN
Measure twice, cut once - RailsConf 2020
Reflections on Alec Clarke’s RailsConf 2020 talk
Using lessons from woodworking, Alec gave some practical tips on how to safely and repeatably write better code.
Safety First
Incremental (Staged) Rollouts
A simple but powerful pattern for incremental feature/version release:
- incrementally roll out a feature over a certain period of time
- ensure that once a user is using the new feature version they don’t flip flop between versions during the rollout period (giving a poor user experience)
- provide an admin interface to abort the rollout without needing to re-deploy
Maintenance Jobs
A testable, less hands-on approach to writing and running one-off jobs (one less reason to console in to production servers)
- create a
MaintenanceJobclass with a date and timestamped version number to ensure the job only ever gets run once - add a class method to run all pending jobs
- add a line to the deploy script which triggers the pending jobs method
Solid Foundations
Proper Preparation
This lesson reminds me of the “make the change easy, and then make the easy change” principle (https://twitter.com/KentBeck/status/250733358307500032).
Alec shows an example of improving (refactoring) the old version before trying to build the new version on top (behind the aforementioned staged rollout flag).
Quality Control
Building a Tool
Building on a previous example, Alec shows an example of creating a Rails generator to make it easy for future developers to create new MaintenanceJobs the right way:
- Create a generator that builds a
MaintenanceJobAND a failing test to implement - Build important logic into the generator so we don’t have to remember important steps
Combined, these techniques lower the barriers to doing things the right way (or at least a good way). I particularly like the way the staged rollout gives an easy way to fix a problem at what otherwise might be a very stressful time… when error monitoring is blowing up and I’m scrambling to figure out a fix.
Thank you to the Ruby Central team for organising the COVID-19 version of RailsConf… RailsConf 2020.2 - Couch Edition (https://railsconf.com)
I plan to do short write-ups of each talk I watch to help cement what I learn.
Today I learned you can use git to compare files, even if they aren’t in a repo!
git diff --no-index file1.txt file2.txt
An issue with Spring caching lead me on a journey of discovery
TLDR; I spent quite a while trying to figure out why ENV variables weren’t being loaded by dotenv-rails. Reloading spring with spring stop was the surprise fix. I learned a lot in the meantime, and since!
I decided to encrypt all personally identifying information (e.g. names and email addresses) in an app I’m hacking away on. It won’t protect them if the application server gets compromised but it adds some protection for the data at rest (you might be surprised how often data is compromised from logs or backups).
Encryption keys are part of an apps configuration and as such, I learned, they don’t belong in the code. In production I will manage the encryption keys through Heroku config vars but I wanted a simple way to manage environment variables in development so I chose dotenv (via the dotenv-rails gem).
Once I had the gem installed and my .env file populated, I fired up the Rails console and was surprised my variables weren’t in ENV. Manually running Dotenv.load worked so I knew the gem was installed and my .env file was able to be found.
After restarting the console a couple more times, the next thing I tried was adding Dotenv::Railtie.load to config/application.rb as per the instructions on making it load earlier. I fired up the console again and they STILL weren’t loaded.
I’d looked through the code on Github and felt like I had a pretty good understanding of what should be happening (and when) but it wasn’t behaving as documented.
At this point I felt like I needed to debug what was going on inside the gem so I figured out how to get the local path to the gem (bundle show dotenv-rails - thanks Stackoverflow!) and then opened the gem in my text editor. In fish shell that can be combined into a single command:
atom (bundle show dotenv-rails)
From there I did some caveman debugging and added puts statements to #load and #self.load to see if I could see them being called. I then restarted the console… still nothing. But now that I had access to the gem I could start testing with rails server rather than rails console. I restarted my dev server and straight away saw:
`self.load` got called
`load` got called
`self.load` got called
`load` got called
=> Booting Puma
=> Rails 6.0.2.1 application starting in development
Sure enough, it works when I start the server (twice, thanks to my addition of Dotenv::Railtie.load) and so the problem is only in Rails console.
After some more digging around in the Github issues I found some reference to a similar problem being caused by spring. As soon as I ran spring stop and restarted the console it worked.
To get to the bottom of this issue I started researching Spring but according to the README, changing the Gem file AND changing config/application.rb should both have caused Spring to restart.
I’ve opened an issue on Spring to see if anyone can help me figure it out but in the meantime I’m happy to have learned a fair bit…
Lessons Learned
- Config belongs in the environment, not in the code: https://12factor.net/config
- The dotenv gem makes managing environment variables simple (including support for different variables in different environments)
- You can find a Gem’s installation path with
bundle show <gem-name> - You can’t pipe the output of that command to open the gem in Atom (at least in fish shell) but you can run it as a sub-command using brackets:
atom (bundle show dotenv-rails) - Spring is a built-in rails mechanism for caching the application to speed up boot times in development (particularly console and tests)
- You can restart Spring with
spring stopor by closing your terminal (the next time you launch something it will start again) - You can tell Spring which files to watch by editing the
config/spring.rbfile
Yesterday I learned you can update a single gem without updating dependencies using bundle update --conservative gem-name
If that update REQUIRES another gem to be updated I’m told you can include just it: bundle update --conservative gem-name other-gem
Thoughtbot: Name the Abstraction, Not the Data - thoughtbot.com/blog/name…
This makes a lot of sense to me. Sacrifice a small amount of DRYness (potentially) to increase clarity and loosen coupling.
Scripts to Rule Them All
Today I configured a new Rails app with Scripts to Rule Them All. It’s a “normalized script pattern that GitHub uses in its projects” to standardise projects and simplify on-boarding. It’s probably premature for an app I’m working on solo… but if you can’t experiment on side-apps, when can you? 😜
I ran into a catch-22 where, the first time you setup the repository, the setup script tries to initialise the database, which relies on the database server being available. The support script that starts the database relies on the setup script (or more specifically, the bootstrap script it calls) already having been run to install the database server. But the setup script relies on the support script… etc, etc
Rather than get fancy I decided to let the developer deal with it. The setup script is idempotent so there’s no harm in running most of it the first time and then all of it the second time. After DuckDuckGoing how to check if Postgres is running and how to write if/else statements in shell scripts I settled on this clause in the setup script:
if pg_isready; then
echo "==> Setting up database…"
bin/rails db:create db:reset
else
echo "==> Postgres is not running (this is normal on first setup)."
echo "==> Launch ‘script/support’ in another console and then try again"
exit 1
fi
echo "==> App is now ready to go!"
Catalina, Ruby and Zsh
I recently upgraded to macOS Catalina (10.15 public beta). There are several “under the hood” changes to the Unix underpinnings which may trip people up. I’m comfortable at the command line but by no means an expert so this post is mainly designed as a reference for future me.
You’ll probably notice the first change when you launch Terminal. If your default shell is set to Bash you will receive the following warning every time:
The default interactive shell is now zsh.
To update your account to use zsh, please run `chsh -s /bin/zsh`.
For more details, please visit [https://support.apple.com/kb/HT208050](https://support.apple.com/kb/HT208050).
FWIW, I think this is an excellent warning message… it states the “problem”, provides instructions on how to fix it and links to a much more detailed article with more information (including how to suppress the warning if you want to use the ancient version of Bash that’s bundled with macOS for some reason).
Personally, I took the opportunity of changing shells to switch to fish shell again. I used it on my last computer but hadn’t bothered to set it up again on this one. It’s a lot less similar to Bash than Zsh but most of the time that’s a good thing (Bash can be quite cryptic and inconsistent). On those occasions where a tool or StackOverflow post doesn’t have fish instructions (and I can’t figure out the fish equivalent myself) it’s usually a simple matter of running bin/bash (or bin/zsh now) to temporarily switch to a supported shell.
The next change you might notice is when you go to use a Ruby executable (e.g. irb). The first time I ran it I received this warning:
WARNING: This version of ruby is included in macOS for compatibility with legacy software.
In future versions of macOS the ruby runtime will not be available by
default, and may require you to install an additional package.
I was a little surprised by this one, not that Ruby was being deprecated (that got a fair bit of coverage in the nerd circles I move in), but because I knew I had installed rbenv, and the latest version of Ruby through that, prior to upgrading to Catalina.
Thankfully the excellent rbenv README had a section on how rbenv works with the PATH and the shims rbenv needs at the start of your PATH for it to work properly.
After changing shells (to Zsh or fish), there’s a good chance that whatever technique you previously used to modify your PATH when your shell session starts is no longer in effect in your new shell.
The README says to run rbenv shell to fix it, however on my machine (regardless of shell) I kept getting a warning that it’s unsupported and to run rbenv init for instructions. You should probably do the same (in case the instructions get updated) but at the time of writing the instructions rbenv init gave for various shells are:
# fish:
> rbenv init
# Load rbenv automatically by appending
# the following to ~/.config/fish/config.fish:
status --is-interactive; and source (rbenv init -|psub)
# Zsh:
% rbenv init
# Load rbenv automatically by appending
# the following to ~/.zshrc:
eval "$(rbenv init -)"
# Bash:
$ rbenv init
# Load rbenv automatically by appending
# the following to ~/.bash_profile:
eval "$(rbenv init -)"
Once you restart your terminal window you should be able to confirm that rbenv is handling ruby versions (via its shims) for you:
> which ruby
/Users/matthew/.rbenv/shims/ruby
> ruby -v
ruby 2.6.4p104 (2019-08-28 revision 67798) [x86_64-darwin18]